Posts
Windows 10 Mobile ~14295 downgrade
In the event this causes grief in the future I wanted to point out the steps to downgrade Windows 10 Mobile build 14295 back to 8.1. The Windows Device Recovery Tool fails to detect the phone without the steps outlined in BrunoTrivellato's response on page 2.
To make this easier, I thought I would repurpose the steps as I can't seem to find an independent or direct link:
- Unplug the phone from the PC.
- Click on "My device was not detected".
- Select your model and you will enter the "Searching Screen".
-
Reboot your phone (pressing volume down + home button for some seconds until it vibrates) and immediately plug it back in the PC.
- If you take too long to plug it in the PC you will have to reboot it again (the Recovery Tool will show a message to you).
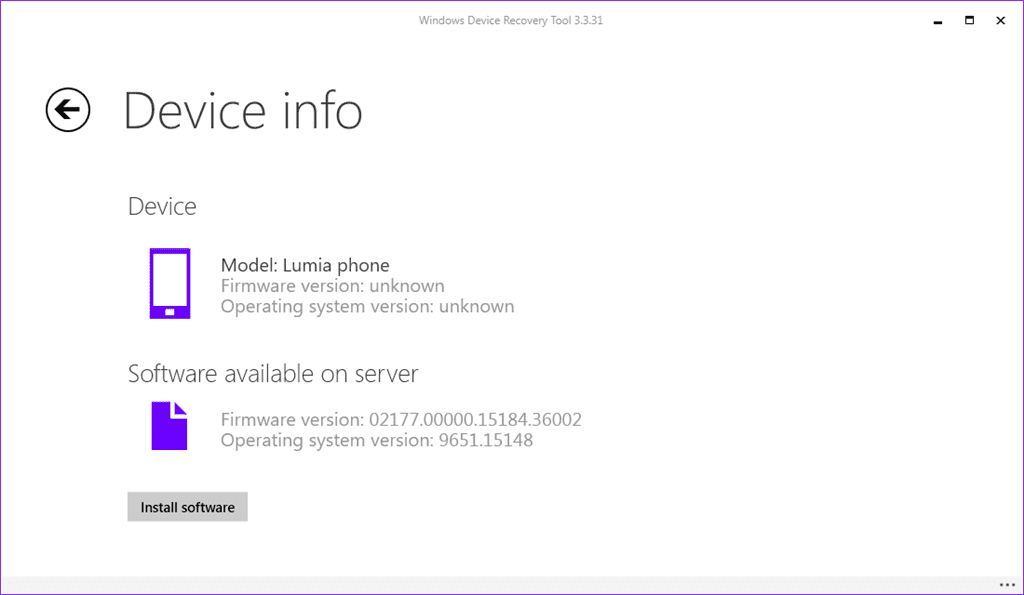
- The tool will recognize your model, but not the OS or Firmware.
- Click in "Download Software" and wait the process to complete.
- When finished, click next and check your Battery as the screen says
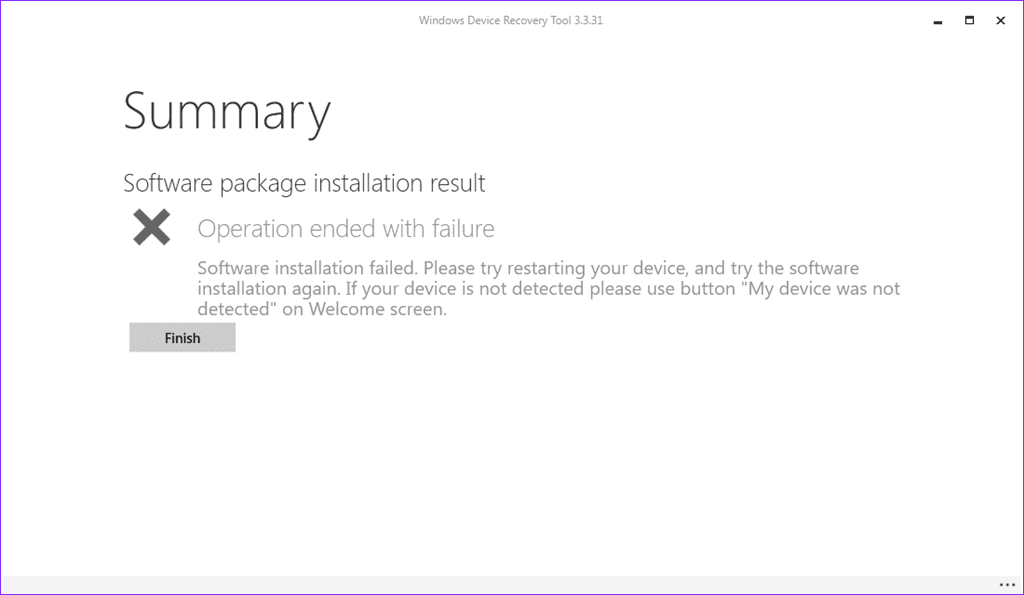
- The next screen will try to install the software BUT IT WILL FAIL, don't worry it is normal. Wait (3-4 minutes) until it fails and click Finish.
' width='1024' height='595' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAAAlCAYAAADyUO83AAAACXBIWXMAAA7DAAAOwwHHb6hkAAAD1klEQVRo3u2a61LqQAzHfWwfSF9CZ/zkF0edcUYd7yKIgsilLbRc2xx%2bgWAPAwgFDtXDzsTsZpO9/JNNt8WdWl6kVRcJHJGmu2qKRrxe6YhX7vR5V%2btw2iqrdofyATX67S/7aMn5B/bMEzihVAq%2b%2bLVQvEpbavlIdtj8%2bko04vWGJ45bE6/uKjV8T1zPUaIPQgb3g0bMPlpy/oF9pVqWXtiVbC4jnW673y5J4PZkB8%2bratinaB0UKV946UO7Va1hzB9aiIwd/gwm/Hvyr0Uko2XHidsl9v%2bEsb5kg%2bMxEYD44seNx/smDz7dfhEAJs31TwAwo3a7LR8fHzMXNGmB04BKS4nmPQK1Wk2enp6kXq/L5%2ben3N3dyf39veRyOa0/Pj5KuVyW5%2bfnUb1SqfweAHq9nlxdXelmz87O5ObmRl5fX%2bX29lay2ay8vb3JxcWFHB0dST6fl5eXFwVsFec3NQA0m009CkEQSBiGSsjh6LVaLSUKgFh90USZKgCSLmxRm01FyNwR0O12R96njjzufeomj7fp73Q6WoebDRw95FBqI8AW5fu%2bZDIZuby8VE4u4Ixz3uEPDw%2ba/MgJEAkQObkCQh%2bOrFqtqi5EG91N5YpokYsQOUCV%2bxxv4kmiwjxMmwgBLApt5BYNkyIGvsljMBcALJqC9/f29uT6%2blrbJDkDIr5ZS5q2yfjmAY86dmZrx2HWReu72%2bGs%2bsoA4DG3u7urQFC4E5RKJSkUCvrc56JULBb1zgAho/3%2b/i6u62qbpwMRYnbcKZBbZKyDZh2vuQAwQxZtmx4HJ80Zf/bVfI7H4LRF40k8SBIjsQEOnqaNV%2blD3mg0tA5wnuepDnX06KMNdxxH9Yme%2bHjYWNTQh5xcgw42NiZt9Jgbsrln7WOhCBhHkkkJcUKZ0OYIsEA2ixxuAFmo2ybgdjSwo8/GsT6IcSDbFH1G6LJJm8%2bOHH2MaXOSdwCJhJ0oAqa99DAok9lGmdw8wTuCedgiAn08hp55jsVhg%2bcABl3kjAE3GZyx4tyigWSKDnWLCuo2DvrwRABM875FAF6KhzsbsTCOJznIjgfeYXGbuflFye4BJDve/ngCnJycyPHxsb4U8YLEi8%2b0ZJM2ShwBAMDmT09P5eDgQPb39%2bXw8FDOz8/1FjjrWTzpo8i83xC%2be54nefYnvgna5SZe7Aa4Ko/8mLfBeb4G/YQSreqjaNo/fCwVAb%2b5bAHYArAFYAvAFoAtAFsADIDBD4VpfIlZ7wvSN78O//4IGAIQOMMICP%2bjCAgH3m56/SNQLQb6Lyl8QflfyPcD/ZeZYq4mfwDVc3hX5funRgAAAABJRU5ErkJggg==' /%3e%3c/svg%3e)
- Repeat steps 1-5.
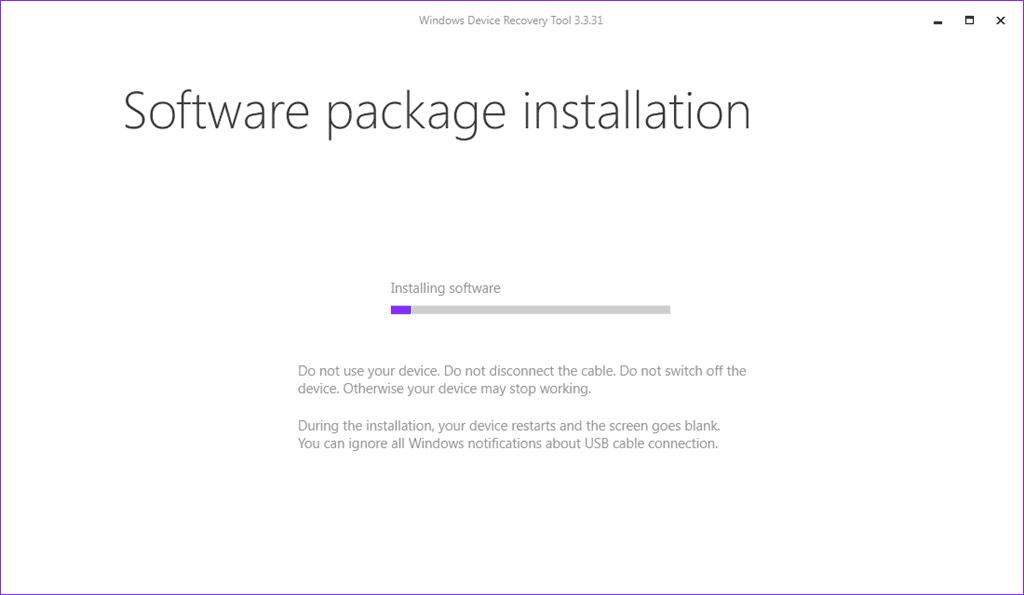
- Now you will see that the screen will not show "Download" but "Install", click it.
' width='1024' height='595' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAAAlCAYAAADyUO83AAAACXBIWXMAAA7DAAAOwwHHb6hkAAAEzUlEQVRo3uVaS0/jVhTO/%2bu%2bqjS7St3Oan5AFyP1F3RXQGKKVIq6aqW20gixGMFikECFiFcQ5AFx3onjR/y6X/1d5zpOGgYbEnDUSCfXPvfazvnueTuFXg0YDQGrD9iDRZOIx2HHhd52w9GTxxx5Lnldb8yPyAjPJ9eLZz4/up7PsfoBOnUTZi%2bA3nHQqwkUKPzyPiIeh4aO/qAHfTiQZJg6BnpfEudI5HE0LSNxvXjm86PrO902/MBDuXID13PC8yasgY8Cd56LRBB%2bCzGm2ePnUHSPzD99Ic%2be/IaZ/ZAfakaBKjJ54ITm8bLStDDZr529z9NAfEi%2byDwKREFqgPjvxfNuNo%2bf9eFZwVsyAJMFrVYLd3d3GA4jxzAajVCpVGBZ1tRNPc9DEAQxz3Gc%2bLzdbsN13YUIsDTPlDQBqx%2bdmaaJzc1NrK2toVqtSh4B0TQN19fXuLi4QLlcluelUkkKSn6j0YBhGLi9vZVrjo6O5Dpeuwg1fjkADBN7e3s4PDyMAaCQV1dXkvb393F%2bfo5isYjj42PUajUcHBxIjel0Ori5ucHl5aUER4G1EgAoH8APd7LZbMYq7Pu%2b5FG9yUuqP82Cqs815JPHY462bct1K2ECSR%2bQxrlldUJ5BGEOALOxf3FhcEVMAFNh8LGdy6NaLwUA2jMd4v39fRwRVEhcZRAyAUDBG1pEWr2BkT3KbB55A%2bxRAB77wfPmHrP/PPmCVBowKSIESp8EPv8i8M/vAr4b8YJgIqzKAh9KYfOmESk1IBrDyhFnH8N6ugkU/45qa8PScXpyKhOfk5MTmTswZWbCpEYmRBx1Xf%2biprwGIJkAcG2gehwd351GADieLX2DImaCJGaOBINOk4J3u105PxgM0O/3ZVKVh6iSTQNCn1f6FGaFLqQp2P0QFH8kBVYC1ut1KTAFJZ/1AQsqCs15gsKRa1hzMFNUNM98cgOAGBd8f74HPnwL/PydgBtGQXZWWs2W3HG1%2bxS61%2btJXnLXCRJJCU8w1Jpk5ZgrAKbtUsCxBFg0jYbL8eQ5NQGxcCHzkidkSoRop6ZpwTJtWe1RZVnp8ZjEeTZOOHKOPDWv1rJq/FJ9kWsAKmWGtUtcldgXKOHs7EzaMet9hjmGQvLYA6AzZAQgcZ4NE/YLuIaApM0glw1IykRoAoLnkkIe/CmvzWNFsz882TLLm09IHQV8L2L%2b9QPw41fAfXGcGzieVHuqtyKl%2blR71SOkWbB4UiGPeQCJ15KviOfkM0q8RCMldSqs0t7f3gm8KQj8%2bjZaZFtRHkBTYPijyqsQSB5NgWGQPK5jCGRIVOaRDJdczzDJ%2b/CYYLw6ALEGjJu7f3wPfFMAfvpajLvFTiikFgvAMpkjBaMgBIDHFIx8NUfinModVNY4myG%2bugnM5gEDTaByJNCtqu6RkKqejAjcuSRP9QiTlPQZilRPMVdO8HWSk5xFAeXJmdNbYR5gGlaoqmbs1JQzW0Tv8KVzgdQAUD13d3extbWFjY0NbG9vY319Xb5A2dnZkTH%2buSEv9y0xvvDgyxCSejFCYvJDT5/Xzu8T2uIPv6BM2/tfJZp5O4wH3%2bGnfYu7eiYwBiB6N8g/SIiV28UnUzBO6PTQBLqaJf%2bSotLU/wOxuuVfZrRKD/8C6K9qS1qfQxgAAAAASUVORK5CYII=' /%3e%3c/svg%3e)
- You will see the installation progress both in the Tool and in your Phone. Wait until it finishes (2-3 minutes).
' width='1024' height='595' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAAAlCAYAAADyUO83AAAACXBIWXMAAA7DAAAOwwHHb6hkAAADq0lEQVRo3u1Y53LiQAzO%2b7/GPcT9TCY/SJn0DOmBHENCqG6YZvB3fCIieznTDKbM2DPyNmlX%2blZbtHtWEeh4QMsG2s6qKRynXr0Ht9YbpoHkmbIsdY3gq35EzWH5Wz5ccvyRPMdp2QPUSz58awC33oVVDLFH45P7wnHqNV3YjgXXc4SavgvHtYXYRmIdU7/VNOTDJccfydcbNfQHAf4U8ugF3WG5gpbTxx5nXlgHQwqToFDShVX/kluVDj/mQz56xh5/owH/Hfxbif9pWts6ydRjMojR%2bhIFLo9IAEwQ5u04SpmoPqKMmGVIVB9R6coAUKFut4tKpTIWYr7VakUaOMmYfr8P3/cxGAwieXu9nvDo1%2bl0pEyearU6zrfbbQRBMLfx0wGccwlYloXX11fU63W8vLzg5OQE9/f3KBaLKBQK%2bPz8xNvbG3K5HJ6fn%2bF5nijNMtvy%2bbyU7%2b7uJCXvx8eH1JOfgBIcLbPfp6cnvL%2b/C%2b/Z2ZnIPT4%2bSjv5KM/%2bmVdQFwVhbgCI/vX1NR4eHnB7eysgUMnz83NR7uLiAqenp1KfyWQEAOZZz/bDw0OUSiXc3Nwgm83i4OBAjLm6usL%2b/r4YQ3AJMol8NJTp0dERLi8vZdzj4%2bMxIOSjPgSA3pI4AHQ9uildn4hzWbCeeSrANnVdfpx5x3GEjy7LGTb7ocEEge3sg2Mx1b7ZD8dSeZaZN/tTmbjLYCYA8dfWbBkaYe4HS980ktwDkjq6Vtl3Yh4QdyaiFJv32FzXlwgAu/SlAKQAJAzAIjFD3J18JzxgHsOS3vE37gHdoA2/7cF1XbngkDRvxgBJnfkbB8Aqt1HMNVCtVeUWyPiiVqsJEQRejHhDnEZRQdCWAwCMLnshsr%2bBzK8OGnYFlXJFAiClcrksV%2bdpxFiCAdHWAjD78eSLwtV41SIPImvzgHBDZ2jccRPxAHO9aqrESO7nmtYIz6zXiI%2bRo0aB2mZGhdw7NArduAfo4FSKGxs3OqZc3ySWdc1zA9R2Ete2trGe/I1GQ%2bp5UpAow/Ca/LZtS548bNsqADhDNIIKMmanwlRelWZKpcnDhxOtVwNZVvmdXAKzHkPjHKFxHmI3BgDXLV2TM2nOPN2bLs18s9mM9ATNU07JdHWzzPyyR2Jie4AaS/c383qeM2U9DWFZ9wnl1zZ9K9RU5XSP2EoA%2bMxlngL6Xqgnwc9TYFLZPD0m8S77mLLz94Blx1vrTTDpd8X0QSQFIAUgBSAFIAUgPgB/AYDsg70wE8JGAAAAAElFTkSuQmCC' /%3e%3c/svg%3e)
JSON Resume
I wanted to mark what feels like an oasis in the desert of a long journey. During my last job search over 2 years ago, I tired of what had become a disjointed resume update routine. Accomplish a task, go to the Word-document-as-one-true-source, update, print to PDF, go to LinkedIn, update, go to careers.stackoverflow.com, update, rinse & repeat.
I yearned for one interchangeable format that allowed me to generate HTML, Word and PDF at the very least. JSON Resume combined with resume-linkedin seemed like a great fit. Unfortunately, due to recent LinkedIn API changes resume-linkedin was all but useless. My first contribution was born out of the realization that if you could get the LinkedIn data through the API console, the process still worked, albeit extremely cumbersome.
As I worked on migrating this site to my personal fork of a theme in Hexo, I thought a custom JSON Resume theme would also be a good fit. These changes to my resume can be found here or here.
Newness
I said in my previous post that a lot can happen in 2 years.
In that time span I've:
-
Moved to using a MacBook and OSX.
- OSX being very BSD-like makes it an prime target for web development. It isn't the second class citizen Windows is in the Ruby or Node.js communities.
-
Transitioned away from .NET and don't really miss it. I do randomly play around with .NET core when possible but I haven't actually built anything with it.
- This was honestly very huge at the time but I still feel I made the right decision. Though Windows 10 is the platform Windows 8 should have been and likely would've kept me on board.
- Transitioned to PHP and web technologies full bore. I'm no fan of the PHP language but in the era of Visual Studio 2012, a dynamic language that only required refreshing my browser was much faster than waiting on the compile cycle.
-
Drank the vagrant koolaid via PuPHPet.
- Recreating production hardware isn't too difficult with my ancient DevOps experience.
- Waiting on the painful commit/push/wait for deployment/refresh cycle to see a change was a huge productivity destroyer.
- Even developing locally when production PHP versions aren't consistent can be a nightmare. Something like rvm in Ruby comes close but it isn't perfect.
- Immediately took to PHPStorm as my IDE of choice. JetBrains have done an amazing job and if you've used ReSharper you've only had a taste. I'm no fan of Java but I'll make a concession for tools this good.
- Wrote a very crude front-end only CMS. When working in only HTML, CSS, and Javascript you really see the separation of client and server very clearly.
-
I jumped in the deep end with tools like gulp, bower and yeoman.
- This has fueled my desire to be a lot more fluent in Node.js.
- Frontend development becomes insanely fun because a lot of the tedium melts away if you do it right.
- This gulp template was extended from this blog post and it's subsequent repository to streamline working on the custom CMS.
- This yeoman gulp generator looks a little more promising as it seems to serve a similar purpose but feels like less work.
- I have a Microsoft Lumia 640 and the Windows 10 Mobile OS is one of the best mobile experiences I've used to date. I know I'm biased but it has shaped up really well.
- My personal laptop is running Windows 10 as well so I haven't abandoned the Windows ecosystem by a long shot, I've just become more of a consumer rather than a developer.
That's really only scratching the surface. It would've been helpful to have blog posts as I moved along but as with most things, life got in the way.
My main goal for the early part of 2016 is to revamp this site and make it the playground I was looking for in 2013. Octopress is really nice but if I upgrade to v3 it's not much more work to migrating away to something like Hexo, Metalsmith, or DocPad.
We be derpin'
A lot can happen in a little over 2 years...
In my last post, I
had proposed an attempt to tackle the FizzBuzz problem. PowerShell was done, PHP was barely started but I never pointed
to it in a subsequent post or finished what I wanted. The project url has
completed and checked solutions for PHP and Node.js. I had mentioned
b. F#, Objective-C, CoffeeScript, C/C++, Go, Dart, and Haskell are the planned languages I've mostly touched in passing or know about.,
as well as C#, Pascal, and Ruby but I may never get to them.
Shortly after that last post, I switched jobs from .NET to web development focusing on PHP with HTML, CSS, and Javascript. That one action shifted much of my focus from most of the languages in that list. With ES6 coming and recently finishing a CodeSchool course in CoffeeScript, the Javascript landscape is looking pretty awesome. Elixir and the Phoenix Framework have recently stood out as upcoming contenders for my mindshare as well.
My last post taught me that while I may know of a language, it doesn't mean I'll have a genuine desire to pursue it. It can also easily become difficult to want to pursue development outside of your day job. Staying current, however, is always worth pursuing. Tooling and efficiency around web development seems to have come a very long way.
To keep this post brief, I plan on making more updates as I feel a lot has changed for me in the past 2 years that I'd still love to share.
JazzHands: Tackling the FizzBuzz problem
Due to a comment on Hacker News (original post here), I thought I would put my money where my mouth was, so to speak, and tackle this problem in a public repository.
My comment could likely be seen as dismissive or arrogant. I get that. My biggest problem is that because people still fail, this is the interview equivalent of patty cake: awkward, childish, and unrewarding (unless you're a 2 year old).
To be quite honest, I don't quite understand my disdain for the problem. It's simple enough that it can be solved a number of ways quickly and gets you to express at least the fundamentals of development in a particular language.
This exercise is an excellent opportunity for a number of things:
- It'll be a form of code kata and I need practice, even on something I dislike greatly.
- Much of my work isn't public, as I often rarely see the benefit of my specific ideas being shared. I don't need to prove anything by doing this but I don't see this hurting anything.
-
If you believe my time tracking is accurate, it should demonstrate at least some proficiency in languages I know and how quickly I can at least have a basic understanding of the ones I don't.
- My proficiency in order is C#, PowerShell, Javascript, PHP, Pascal, then Ruby. The latter 3 don't rattle around in my brain as much as the former.
- F#, Objective-C, CoffeeScript, C/C++, Go, Dart, and Haskell are the planned languages I've mostly touched in passing or know about.
- This would be a good opportunity to write tests to check the work. A neutral 3rd party would be ideal as the tests could influence the experiment.
- It'll also give insight into my habits regarding structure and clean, concise code. I prefer readable code with very little comments because I feel the code itself should be the comment. This largely isn't possible in most code bases but it shouldn't really be a problem here.
- To prove to myself that I don't just take examples from Google and make them my own, that I can start from scratch when I need to.
Note: I'm using https://rosettacode.org/wiki/FizzBuzz as a language guide only. If you see me follow a specific example, punch me in the nuts.
The best description of the problem can be found here, specifically (altered for this example):
Write a program that prints the numbers from 1 to 100. But for multiples of three print "Jazz" instead of the number and for the multiples of five print "Hands". For numbers which are multiples of both three and five print "JazzHands".
This brings up some excellent points. I'm definitely not above FizzBuzz or live coding but I still can't pinpoint why I have beef with this particular problem.
I honestly can't remember the last time I've actually tackled this problem so the potential to look really foolish, at least at the beginning, is pretty high.